Nous n’utilisons que 10 % de notre cerveau. Faire craquer ses articulations donne de l’arthrite. Google pénalise le duplicate content. Le point commun entre ces trois affirmations ? Elles sont toutes fausses ! Eh oui, certaines idées reçues ont la vie dure !
Je vous propose aujourd’hui de déconstruire un mythe très présent sur la Toile. Pour cela, nous verrons ce qu’est le duplicate content et pourquoi il n’est pas pénalisé par Google (sauf en cas de vol avéré de contenus).
Pour être vraiment exhaustif sur le sujet, je vous expliquerai aussi quels sont les différents types de duplicate content, leurs causes et les moyens de s’en prémunir.
Avant de débuter votre lecture, si vous souhaitez améliorer le SEO de votre boutique en ligne, téléchargez gratuitement notre livre blanc seo.

SOMMAIRE :
- Définition du duplicate content
- Les différents types de duplicate content
- Le duplicate content et les pénalités Google : la fin d’un mythe
- 7 causes majeures de duplicate content
- Comment éviter le contenu dupliqué ?
- Comment corriger le duplicate content simplement ?
Définition du duplicate content
Le duplicate content, ou contenu dupliqué en français, repose sur la présence de deux pages identiques ou quasi-identiques sur le Web.
En soi, cela n’a rien de bien dramatique. Mais cela représente tout de même un problème pour Google. Alors, quand il scanne deux pages au contenu identique, un choix s’impose à lui. L’une des deux intégrera son index, tandis que l’autre sera mise aux oubliettes.
Pourquoi ne garde-t-il pas les deux ?
Pour faire des économies d’une part (l’indexation des pages coûte cher… très cher !) et, d’autre part, pour proposer aux internautes des contenus uniques qui apportent des réponses et de la valeur ajoutée.

Les différents types de duplicate content
Duplicate content partiel
Il faut savoir qu’un contenu n’a pas besoin d’être 100 % identique à un autre pour être considéré comme dupliqué. Il existe ce que l’on appelle le duplicate content partiel. Cela arrive lorsque deux pages ont des contenus très proches, qui ne diffèrent que par quelques mots ou quelques phrases.
On retrouve souvent ce type de duplicate content sur les sites e-commerce, au niveau des fiches produits d’articles très similaires par exemple.
Exact duplicate content
Son nom parle de lui-même : l’exact duplicate content correspond à deux contenus totalement identiques. Cela peut arriver lorsque deux URL différentes mènent sur une seule et même page par exemple.
Nous verrons cela plus en détail dans la partie consacrée aux causes du contenu dupliqué.
Duplicate content interne
Cela se produit lorsque deux pages d’un même site proposent des éléments textuels identiques. Généralement, le duplicate content interne est involontaire et résulte de petits soucis de paramétrage du site.
Duplicate content externe
Le duplicate content externe se produit lorsque le même contenu est publié sur deux sites différents. Il s’agit de la forme de duplicate content qui effraie le plus les propriétaires de sites web, car elle peut parfois être synonyme de vol de contenu.
interne partiel
interne exact
externe partiel
externe exact
Le duplicate content et les pénalités Google : la fin d’un mythe
Google ne l’a que trop répété : le duplicate content n’entraîne pas de pénalité. En tout cas, pas au sens strict du terme.
Bien entendu, entre deux contenus identiques, seul celui considéré comme étant l’original sera pris en compte par le moteur de recherche. Cela ne veut pas dire que « la copie » sera sanctionnée. Elle sera tout simplement ignorée…

Il existe un seul cas de duplicate content justifiant une pénalité Google : le vol de contenu. Les sites qui comportent un grand nombre de contenus dérobés peuvent en effet être punis, par Google tout d’abord, mais aussi par la loi.
Toutefois, je préfère vous prévenir : si vous êtes victime de ce genre de pratique, mieux vaut tenter de résoudre le problème à l’amiable avec le site pirate. En effet, les procédures administratives et judiciaires sont souvent longues, compliquées et fastidieuses.
Bien que Google ne pénalise pas le contenu dupliqué involontaire, il convient tout de même de l’éviter, car :
- le contenu dupliqué interne génère des pages qui ne seront pas prises en compte dans l’index du moteur de recherche, ce qui vous fait perdre des opportunités ;
- en cas de duplicate content externe, votre page pourrait être ignorée au profit de celle présente sur un site plus important, plus populaire ou plus ancien.
7 causes majeures de duplicate content
1. La navigation à facettes
Il s’agit d’une source de duplicate content très courante sur les sites e-commerce. La navigation à facettes génère des doublons lorsque les facettes ne sont pas optimisées pour le SEO.
D’accord, mais une facette, c’est quoi ?
C’est une option donnée à l’internaute pour faciliter sa recherche d’article sur un e-shop. Il s’agit d’un filtre qui va générer une URL en fonction des critères sélectionnés par l’internaute.
Par exemple, vous vendez des vêtements de sport et l’un de vos visiteurs recherche un short de fitness pour homme, taille M, coloris bleu. Il va donc se rendre sur la page de catégorie des shorts pour homme et sélectionner les facettes correspondantes :
- sport : fitness ;
- taille : M ;
- coloris : bleu.
Cette recherche à facettes va générer une URL du type :
- vetementsdesport.fr/short-homme.html?sport=fitness&size=m&color=blue
Imaginons maintenant que notre internaute recherche toujours le même article, mais qu’il ait cliqué sur les facettes dans l’ordre suivant :
- coloris : bleu ;
- taille : M ;
- sport : fitness.
L’URL générée par cette recherche sera alors la suivante :
- vetementsdesport.fr/short-homme.html?color=blue&size=m&sport=fitness
Comme vous pouvez le voir, les deux URL sont différentes mais, au final, la page affichée sera la même.

Étant donné que les URL ne sont pas identiques, Google va considérer qu’il s’agit de deux pages différentes avec un contenu similaire. Cela entraîne donc du duplicate content interne.
Lorsque les facettes ne sont pas correctement configurées, les combinaisons sélectionnées par les internautes peuvent générer des centaines, voire des milliers d’URL différentes, et donc énormément de duplicate content.
2. Le moteur de recherche interne
De nombreux sites internet disposent d’un moteur de recherche interne.
Mais si ! Vous savez, c’est la petite loupe qui vous permet de trouver ce que vous voulez sur un site.
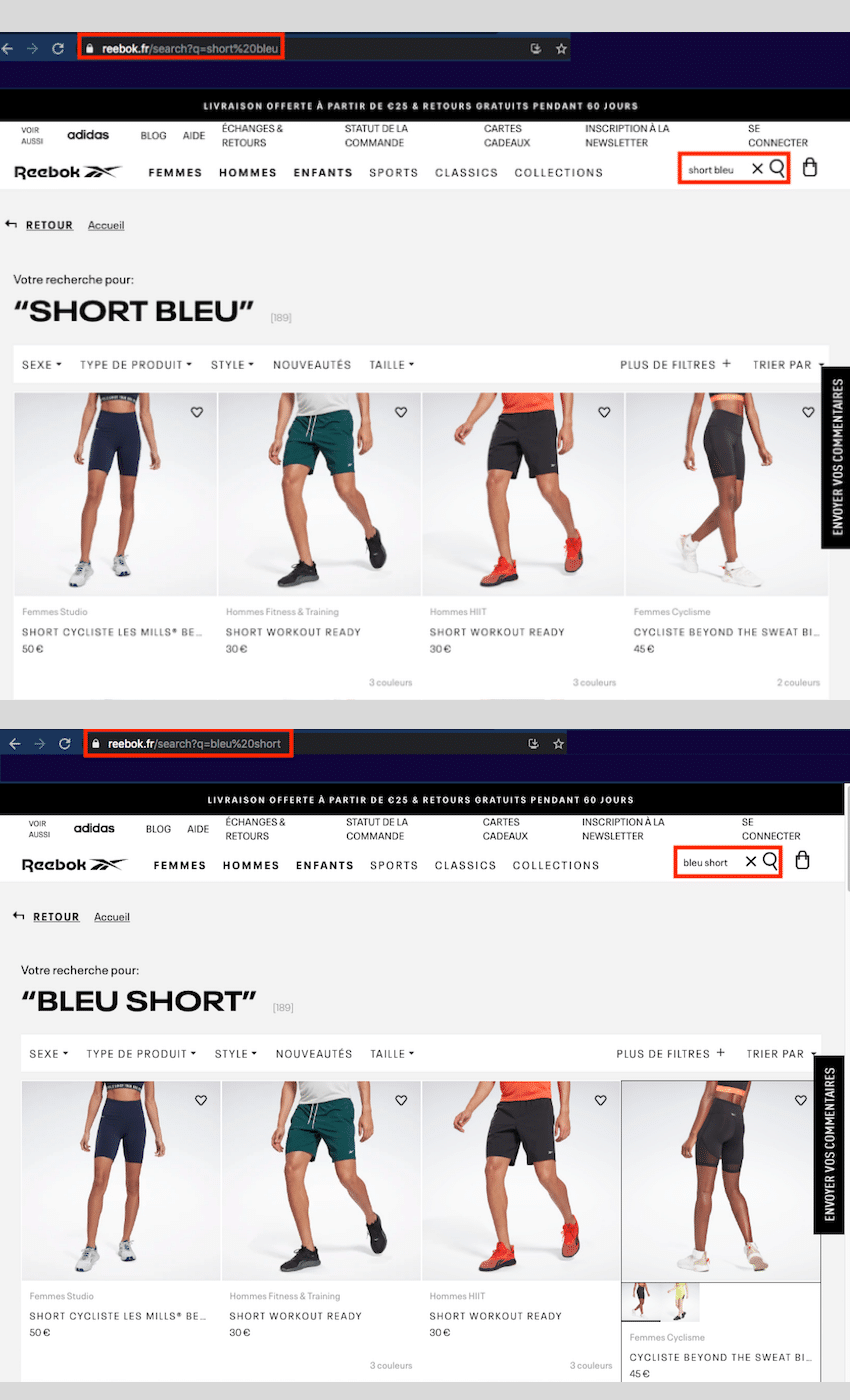
Eh bien, lorsqu’un internaute tape quelque chose dans ce moteur de recherche, cela génère une URL qui ressemble à ça :
- vetementsdesport.fr?q=short%20bleu
Mais, si au lieu de taper short bleu votre visiteur tape bleu short, l’URL sera la suivante :
- vetementsdesport.fr?q=bleu%20short
Comme pour la navigation à facettes, nous avons des URL différentes, mais qui afficheront la même page. Pour Google, il s’agit donc de contenu dupliqué.
3. Les fiches produits trop similaires
Rédiger des fiches produits originales pour des articles qui se ressemblent peut relever du casse-tête.
C’est un problème que rencontrent de nombreux e-commerçants !
Par manque d’inspiration, pour gagner du temps, ou tout simplement parce qu’il n’est pas possible de faire autrement, beaucoup de fiches produits sont donc dupliquées pour tout ou partie.
Encore une fois, rassurez-vous. Votre site ne sera pas pénalisé pour cela. En revanche, Google pourrait bien ignorer bon nombre de vos fiches, vous faisant ainsi perdre des opportunités de ventes.
Pour aller plus loin, vous pouvez également consulter cet article sur le sujet : Duplicate Content des Fiches Produits : Comment l’éviter ?
4. Les paramètres de tracking
Vos paramètres de tracking peuvent également engendrer des URL différentes pour une même page. Par exemple, vous pouvez utiliser un code UTM (Urchin Tracking Module) pour connaître « la provenance » de vos visiteurs et suivre leur visite sur votre site.
Ainsi, si vous « trackez » les internautes qui arrivent sur votre site à partir de votre newsletter par exemple, les deux URL suivantes pourraient mener à votre page d’accueil :
- vetementsdesport.fr/accueil/
- et vetementsdesport.fr/accueil.html?utm_source=newsletter
La coexistence de ces URL pour une même page sera de facto considérée comme du duplicate content par Google.
5. Le HTTP et HTTPS
C’est un souci que l’on rencontre de moins en mois souvent, mais cela arrive encore de temps en temps.
Si votre site est accessible à la fois en HTTP et en HTTPS, Google considérera cela comme des pages distinctes, ce qui crée du duplicate content.
Par exemple, https://www.vetementsdesport.fr et http://www.vetementsdesport.fr peuvent renvoyer sur une seule et même page, mais cela sera considéré comme un doublon aux yeux de Google.
6. La casse des URL (majuscules et minuscules)
Il est important d’uniformiser la casse de vos URL afin que Google ne les considère pas comme des pages différentes. En effet, le moteur de recherche est sensible à ce paramètre qui peut sembler anodin.
Si les deux URL suivantes dirigent les internautes vers votre page d’accueil, celle-ci sera vue comme dupliquée :
- vetementsdesport.fr/accueil/
- vetementsdesport.fr/Accueil/
7. Le site de pré-production
Dernier facteur de contenu dupliqué, et non des moindres : les sites de pré-production.
Cela se produit lorsque vous avez déjà un site web en ligne et que vous travaillez à l’élaboration d’une nouvelle version de ce dernier. Si elle est détectée par Google, cette version dite de pré-production pourrait générer du duplicate content en quantité astronomique !
Vous courez même le risque que le moteur de recherche considère votre site de pré-production comme l’original, et votre site d’origine comme une copie. Autant vous dire que les effets, en termes de SEO, peuvent se révéler catastrophiques.
Comment éviter le contenu dupliqué ?
Pour éviter le duplicate content, il faut tout d’abord être en mesure de le détecter. Les outils et les méthodes à utiliser ne seront pas les mêmes pour du duplicate content interne ou externe.

Vérifier le duplicate content interne
Pour mettre en évidence le contenu dupliqué sur un même site, il existe des outils SEO tels qu’Ahrefs, Siteliner ou Screaming Frog. Voyons un peu plus en détail leurs fonctionnalités…
Ahrefs
Ahrefs pour commencer est un outil SEO all-in-one. C’est-à-dire qu’il dispose de nombreuses options utiles au suivi et au perfectionnement de votre référencement naturel. Parmi ces fonctionnalités, on retrouve la détection du duplicate content interne.
Lorsque vous auditez votre site avec Ahrefs, le logiciel va inspecter la totalité de vos pages et vous signaler les éventuels problèmes, comme celles ayant un contenu similaire.
Envie de voir un exemple d’audit de site Ahrefs ? C’est par ici : Ahrefs’ Site Audit Tutorial
Cet outil est extrêmement complet et s’avère être d’une aide précieuse pour optimiser votre site. Toutefois, comme d’autres outils de cette qualité, il est payant (à partir de 99$ par mois).
Screaming Frog
Screaming Frog, quant à lui, est un « crawler » SEO. En clair, c’est un logiciel qui se comporte comme les robots de Google : il va découvrir vos pages et en analyser le contenu. Mais à la différence des Googlebots, il va vous donner le détail de son analyse.
Il vous signalera, entre autres, les pages de votre site qui comportent du contenu dupliqué exact ou partiel.
Screaming Frog est ce que l’on appelle un freemium. C’est-à-dire que les fonctionnalités de base sont gratuites, et pour bénéficier des options plus avancées il faut payer une licence.
Bonne nouvelle !
À l’heure où je rédige ces lignes, la détection de duplicate content interne fait partie des fonctionnalités gratuites (dans la limite de 500 URL).
Pour plus de détails, n’hésitez pas à visionner la vidéo de présentation de Screaming Frog.
Siteliner
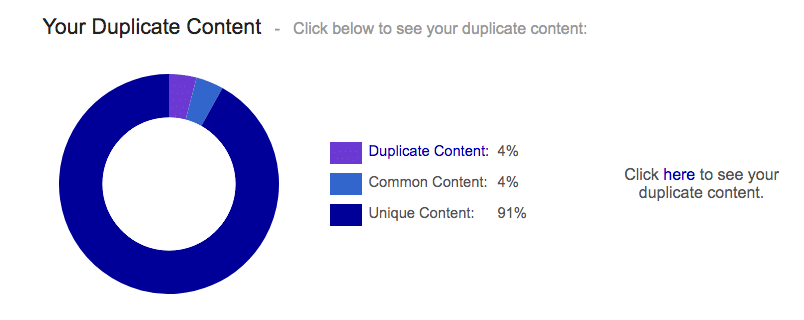
Siteliner est un logiciel freemium qui permet d’auditer rapidement votre site web pour détecter les contenus dupliqués en interne et les liens cassés.
Il analyse aussi d’autres paramètres intéressants tels que la vitesse de chargement moyenne de vos pages ou encore le nombre de mots moyen par page.
Dans sa version gratuite, le scan se coupe au bout de 250 pages analysées. Vous devrez souscrire à la version premium pour aller au-delà (jusqu’à 25 000 pages en tout).
Les outils pour détecter le duplicate content externe
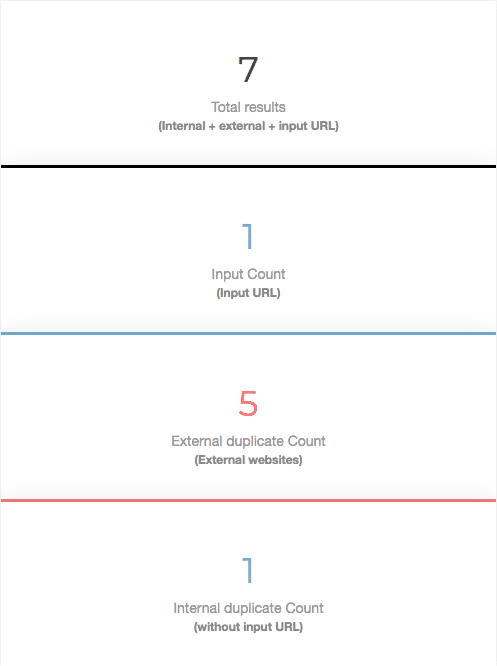
Duplicate content checker
Cet outil édité par SEO Review Tools est un logiciel gratuit qui vous aide à déceler le duplicate content externe. Deux options de détection sont accessibles. Vous pouvez :
- indiquer l’URL à vérifier dans la barre de recherche et l’outil vous indique les pages au contenu similaire ;
- copier un morceau de texte à vérifier et l’outil vous indique les pages comportant un texte identique (dans la limite de 150 mots).
Copyscape
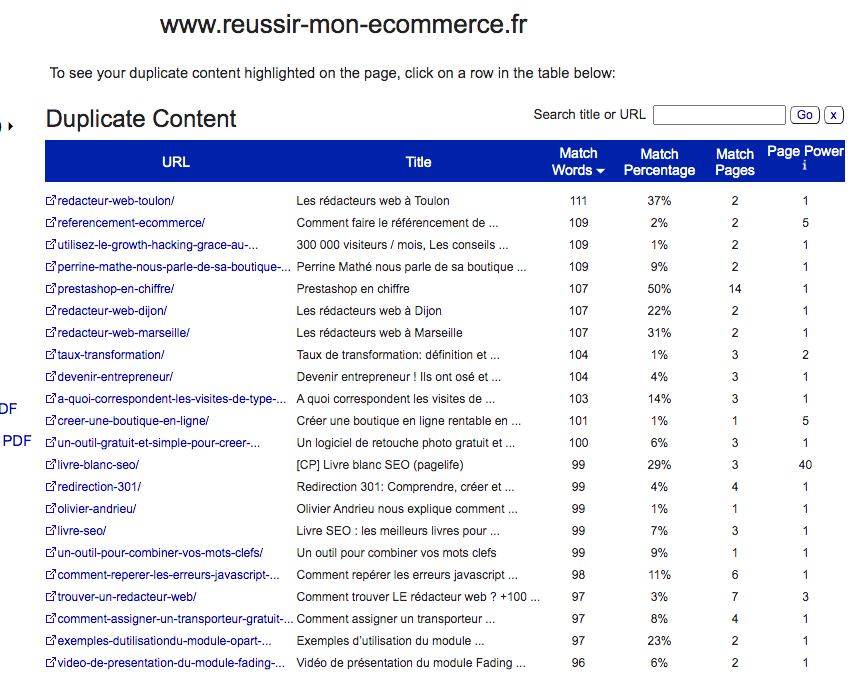
Copyscape est un logiciel de détection de duplicate content qui fonctionne en mode freemium.
Vous pouvez analyser vos URL gratuitement pour savoir s’il existe sur le web des pages qui copient votre contenu. Si Copyscape trouve des pages avec des textes similaires aux vôtres, il vous en donne l’URL, le pourcentage de mots « copiés » et surligne les extraits concernés. Avec la version gratuite, vous n’aurez accès qu’aux 10 premiers résultats.
Voici une vidéo qui vous explique les fonctionnalités gratuites et payantes de cet outil : About Copyscape.
KillDuplicate
Voilà un outil ultra complet pour détecter le duplicate content externe ! KillDuplicate vous permet de scanner l’ensemble des pages de votre site et vous donne les URL qui reprennent votre contenu de manière exacte ou partielle.
Vous pouvez directement vérifier dans l’outil quelles sont les parties de vos textes qui sont copiées et voir si le site « copieur » fait un lien vers le vôtre.
En cas de vol de contenu, KillDuplicate vous propose même une procédure pour résoudre le problème, allant de l’e-mail au propriétaire du site (avec des modèles tout prêts en français et en anglais), jusqu’au dépôt de plainte.
Cet outil offre tellement de fonctionnalités pour automatiser la résolution des soucis de duplicate content qu’il serait trop long de toutes les détailler ici. Je vous laisse donc consulter cette petite vidéo de présentation du logiciel.
Comme pour Ahrefs, il s’agit d’un outil payant. KillDuplicate vous propose des abonnements à partir de 17 € par mois.
Comment corriger le duplicate content simplement ?
Il existe tellement de manières de corriger le duplicate content que cela pourrait faire l’objet d’un livre ! Plutôt que de toutes les détailler ici, je vous propose plutôt de voir une méthode simple, en 3 étapes, qui permet de résoudre une bonne partie des soucis évoqués dans cet article.
Qu’est-ce que vous en dites ? Voici comment procéder…

1. Trouver la source du problème
Tout d’abord, il faut comprendre d’où vient le problème de duplicate content rencontré. S’agit-il :
- d’un module mal configuré (comme pour la navigation à facettes) ;
- de doublons engendrés par une mauvaise architecture du site ;
- de manque d’uniformité dans les URL… ?
Passez en revue tout ce que nous avons évoqué dans la partie consacrée aux causes du duplicate content.
2. Utiliser la balise canonical
La plupart des problèmes de contenu dupliqué peuvent être résolus grâce à la balise canonique (canonical en anglais). Celle-ci s’insère dans le code source de vos pages (code HTML) et indique à Google quelle est la page d’origine à prendre en compte.
Cela fonctionne pour le duplicate content interne, mais c’est aussi un moyen de se prémunir face au vol de contenu. Généralement, les « pirates » se contentent de copier-coller vos pages telles quelles et en reprennent même le code source.
Or, si vous y avez placé une balise canonical indiquant la page d’origine, Google saura où trouver le contenu source (le vôtre) et ignorera celui qui a été volé.
Pour tout savoir sur cette balise, je vous recommande la lecture de cet article : URL canonique : définition et utilisation pour un bon SEO !
3. Bloquer la détection des pages dupliquées
Vous n’êtes pas en mesure de corriger le duplicate content présent sur vos pages ? Alors, en dernier recours, vous pouvez « masquer » le problème aux yeux de Google.
Pour ce faire, vous pouvez utiliser le fichier robot.txt et la balise noindex. Cela vous permettra de dire à Google que vous ne souhaitez pas indexer ces pages, et votre budget crawl sera préservé.
Commencez par placer une balise meta robots noindex sur les pages qui contiennent du duplicate content. Une fois que Google aura supprimé ces pages de son index, utilisez la commande disallow dans votre fichier robots.txt pour empêcher le moteur de recherche de découvrir ces pages à l’avenir.
Vous trouverez davantage d’informations dans la partie « Comment empêcher l’indexation Google ? » de mon article consacré à l’indexation Google.
Petite précision : si vous ne maîtrisez pas le fichier robots.txt, ne le modifiez pas vous-même. Confiez cette tâche à un prestataire ! Une mauvaise manipulation et c’est tout votre site qui pourrait être désindexé.
Vous voyez… Finalement le duplicate content, ce n’est pas si dramatique que ça. Il en existe de nombreuses causes, mais il y a des outils et des solutions pour y remédier. Et, même si vous n’arrivez pas à corriger vos contenus dupliqués immédiatement, Google ne vous en tiendra pas rigueur !
En attendant, concentrez vous sur d’autres aspects SEO importants à travailler sur votre site pour un meilleur référencement naturel. Vous voulez savoir lesquels ? Alors téléchargez gratuitement ce livre blanc ;)
Notez toutefois qu’il est toujours mieux de corriger vos pages dupliquées. Si vous ne savez pas comment procéder, vous pouvez toujours faire appel à un expert. Sinon, notez le problème quelque part et revenez-y plus tard, lorsque vous aurez trouvé la solution.
En parlant de solution… Celle-ci se trouve sans doute dans ma formation SEO Ready ? Je vous y explique comment résoudre les problèmes qui bloquent votre référencement naturel.
Passionné d’e-commerce et de SEO, je suis le créateur du site reussir-mon-ecommerce.fr. Depuis plus de 15 années, j’aide les e-commerçants à développer sainement leur entreprise. Et si je ne suis pas devant mon écran, c’est que je suis derrière ma batterie à jouer du rock ! !
Merci pour cet article très intéressant !
De rien 😉
Bonjour Olivier,
Tout d’abord, je tenais à vous remercier pour votre article qui m’est très utile.
J’ai ouvert mon site e-commerce voilà maintenant un peu plus de deux ans. Je ne suis pas né avec un ordinateur entre les mains vu mon âge (58 ans).
J’ai donc des lacunes dans tous les secteurs :), je fais au mieux et j’apprends tout sur le tas.
Ma question est la suivante :
Serait-il judicieux d’indexer manuellement toutes les variantes (que les robots n’indexent pas) d’un produit sur la « Google search console » ?
J’avoue, travail contraignant, fastidieux, mais si c’est utile, pourquoi pas ?
Bonjour Thierry,
non c’est en effet fastidieux et il y a mieux à faire 🙂.
Travaillez la popularité de votre site ça aidera non seulement à améliorer le positionnement des pages déjà indéxée mais améliorera aussi la rapidité d’indexation des pages qui ne le sont pas encore (indexées).